Pipeline
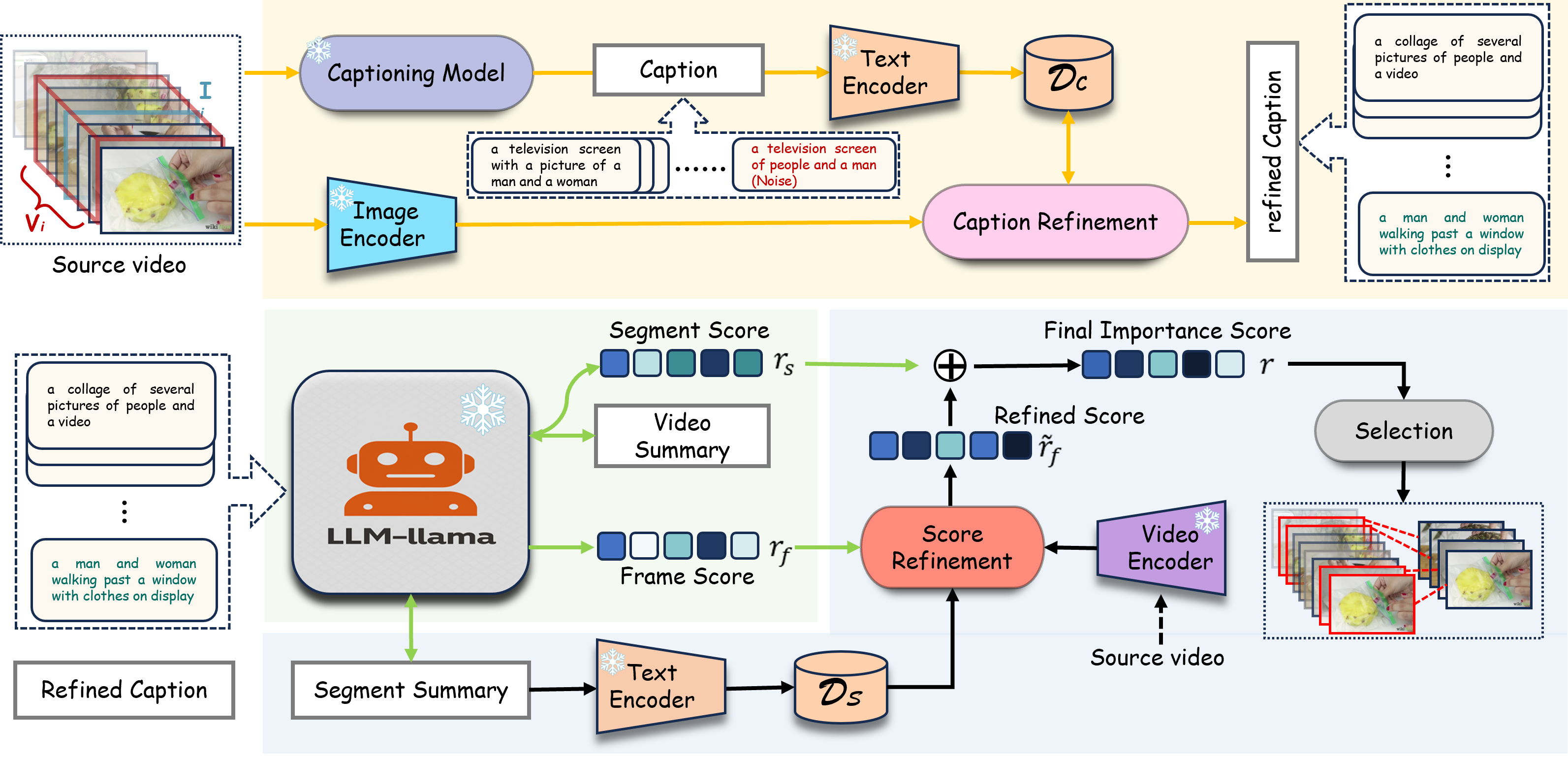
Conventional video summarization relies heavily on annotated datasets, limiting generalization. To address this, we propose TF-SUM, a training-free framework that harnesses the reasoning power of LVLMs and LLMs. Instead of task-specific training, TF-SUM generates frame-level descriptions via LVLMs and performs hierarchical importance inference purely in the language space. Extensive experiments on four benchmarks show that TF-SUM matches or outperforms state-of-the-art methods without using a single training sample.
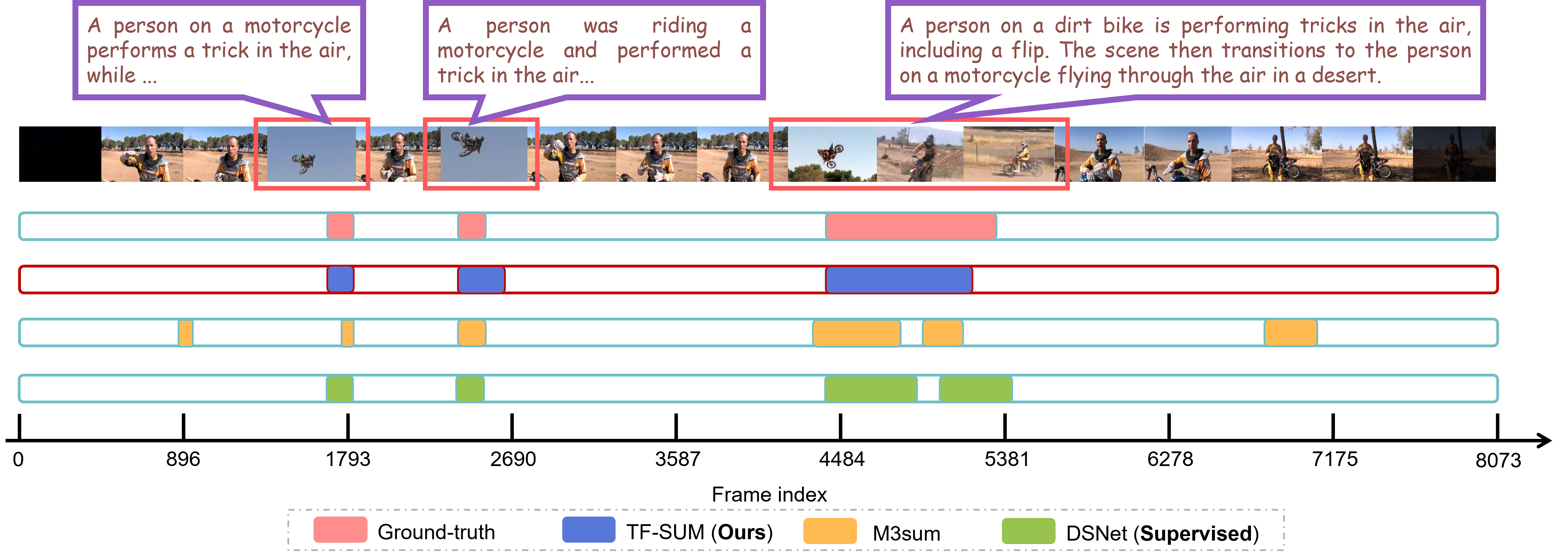
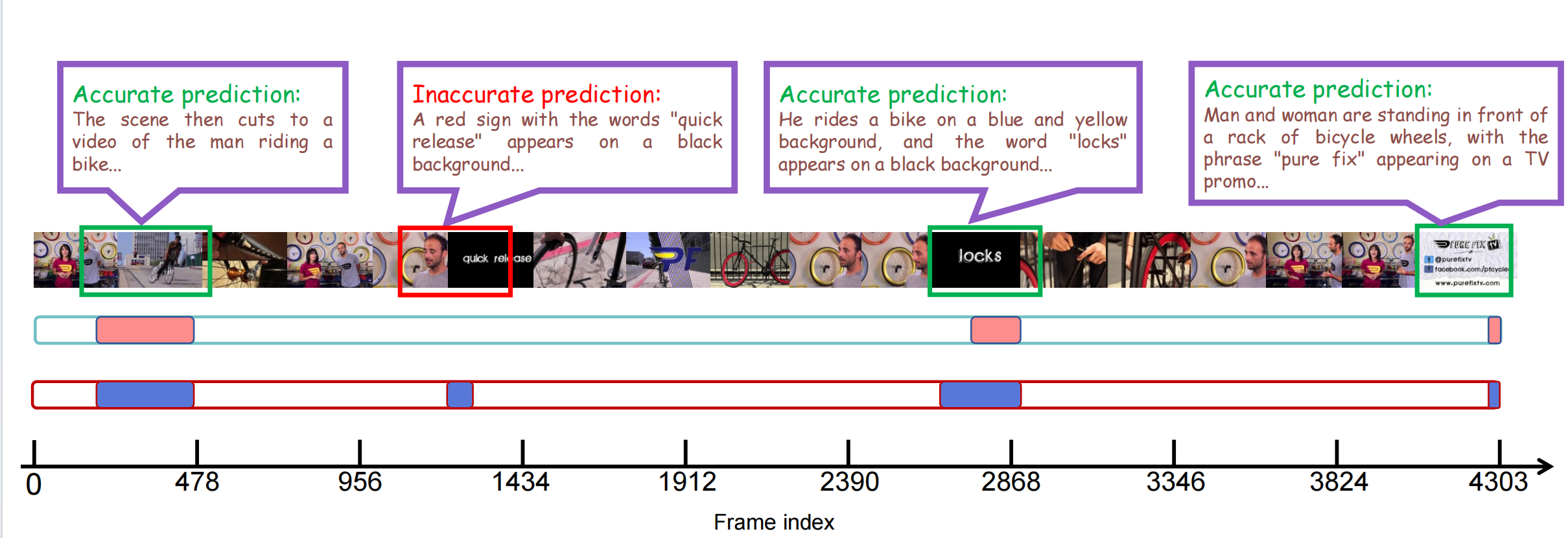
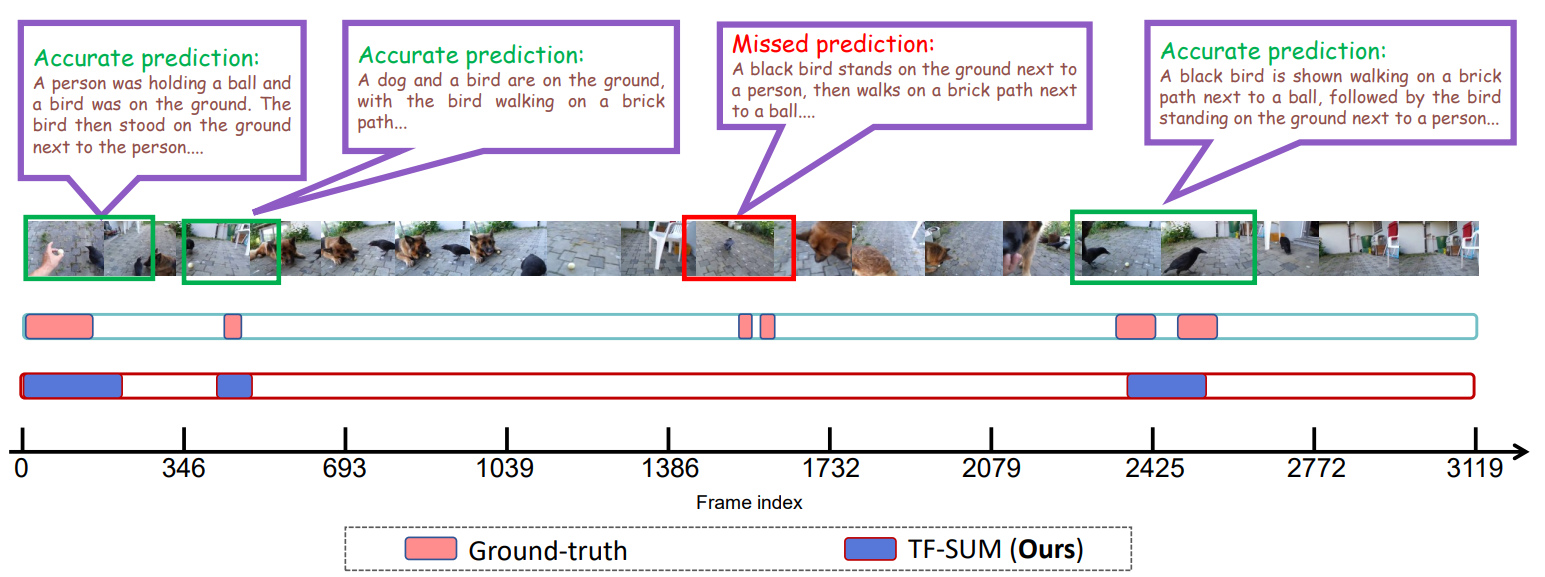
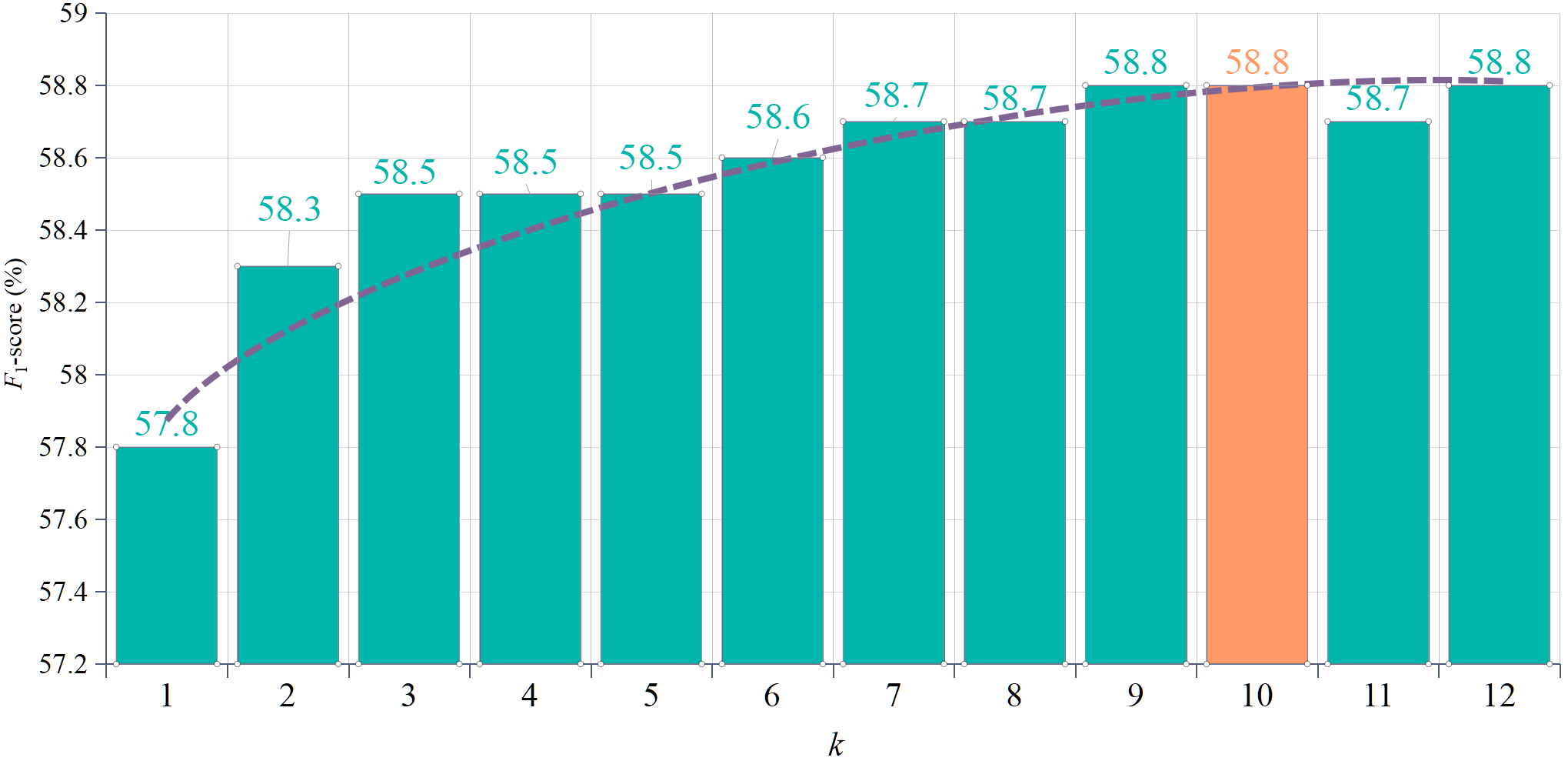
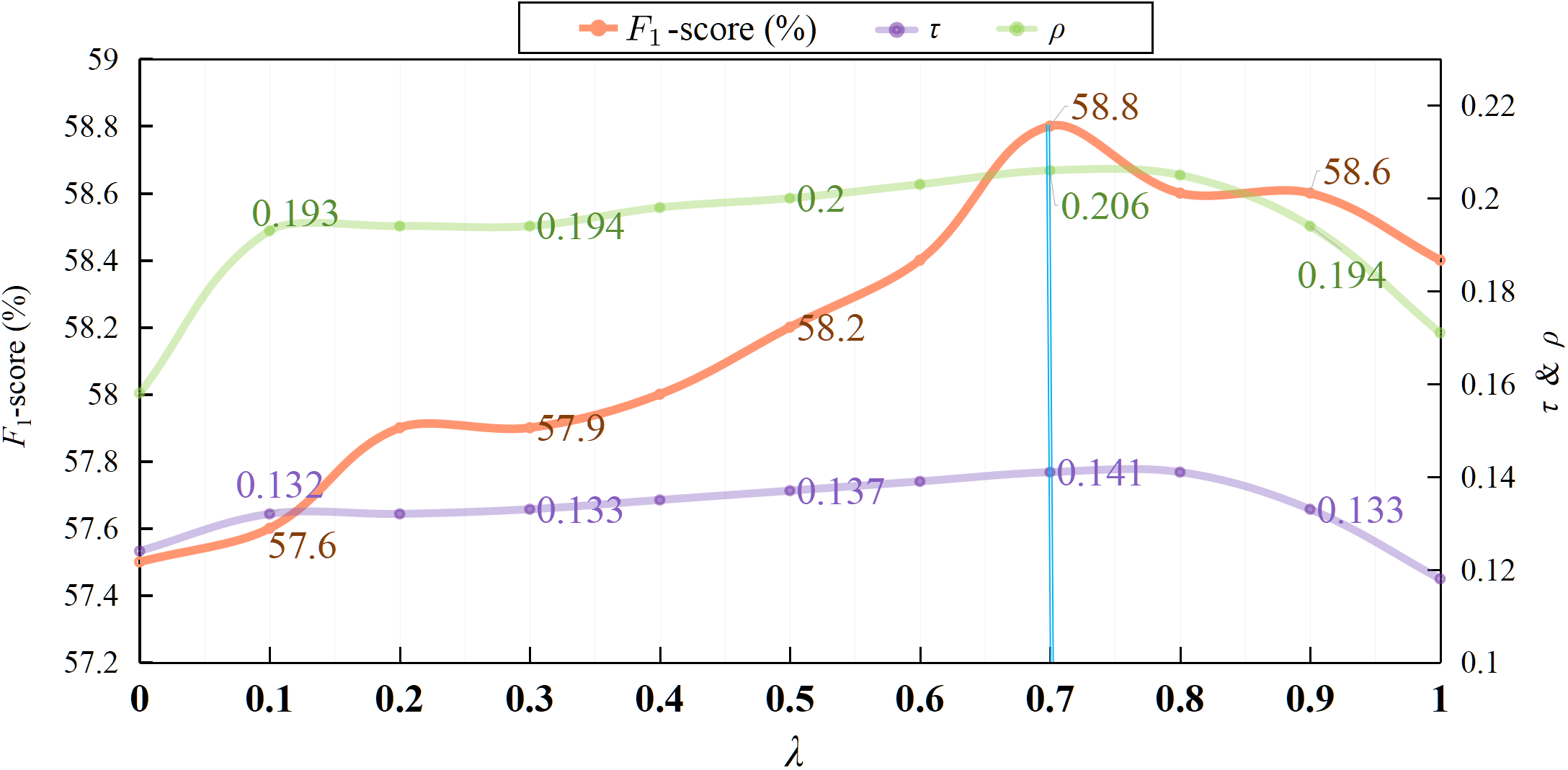
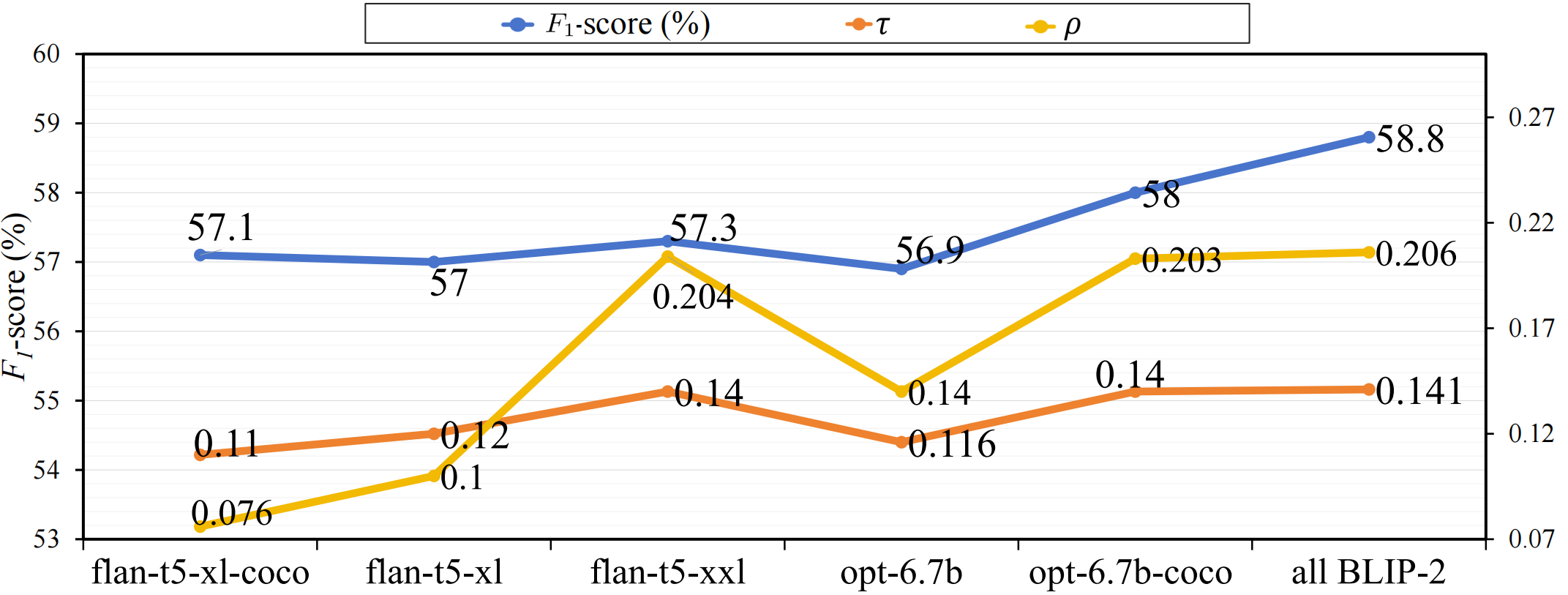
BibTex Code Here